JVM
JVM
JIT优化技术
有了JIT技术之后,JVM还是通过解释器进行解释执行。但是,当JVM发现某个方法或代码块运行时执行的特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。然后JIT会把部分“热点代码”翻译成本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用。
要想触发JIT,首先需要识别出热点代码。目前主要的热点代码识别方式是热点探测(Hot Spot Detection),有以下两种:
1、基于采样的方式探测(Sample Based Hot Spot Detection):周期性检测各个线程的栈顶,发现某个方法经常出现在栈顶,就认为是热点方法。好处就是简单,缺点就是无法精确确认一个方法的热度。容易受线程阻塞或别的原因干扰热点探测。
2、基于计数器的热点探测(Counter Based Hot Spot Detection)。采用这种方法的虚拟机会为每个方法,甚至是代码块建立计数器,统计方法的执行次数,某个方法超过阀值就认为是热点方法,触发JIT编译。
在HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器和回边计数器。
方法计数器。顾名思义,就是记录一个方法被调用次数的计数器。
回边计数器。是记录方法中的for或者while的运行次数的计数器。
JVM的运行时内存区域
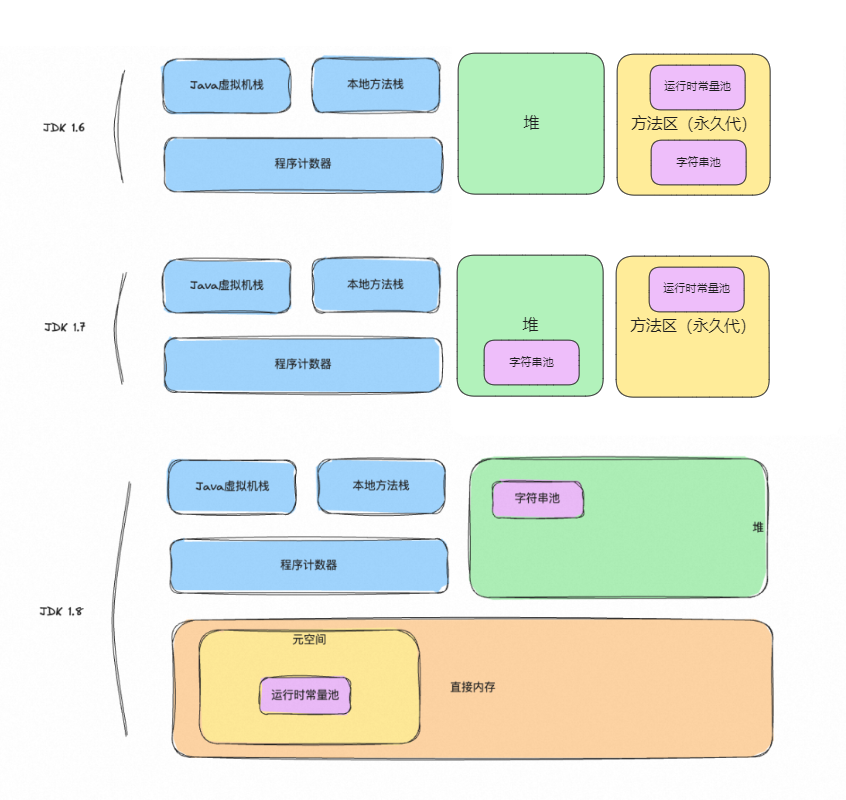
程序计数器:一个只读的存储器,用于记录Java虚拟机正在执行的字节码指令的地址。它是线程私有的,为每个线程维护一个独立的程序计数器,用于指示下一条将要被执行的字节码指令的位置。它保证线程执行一个字节码指令以后,才会去执行下一个字节码指令。
Java虚拟机栈:一种线程私有的存储器,用于存储Java中的局部变量。根据Java虚拟机规范,每次方法调用都会创建一个栈帧,该栈帧用于存储局部变量,操作数栈,动态链接,方法出口等信息。当方法执行完毕之后,这个栈帧就会被弹出,变量作用域就会结束,数据就会从栈中消失。
本地方法栈:本地方法栈是一种特殊的栈,它与Java虚拟机栈有着相同的功能,但是它支持本地代码( Native Code )的执行。本地方法栈中存放本地方法( Native Method )的参数和局部变量,以及其他一些附加信息。这些本地方法一般是用C等本地语言实现的,虚拟机在执行这些方法时就会通过本地方法栈来调用这些本地方法。
Java堆:是存储对象实例的运行时内存区域。它是虚拟机运行时的内存总体的最大的一块,也一直占据着虚拟机内存总量的一大部分。Java堆由Java虚拟机管理,用于存放对象实例,是几乎所有的对象实例都要在上面分配内存。此外,Java堆还用于垃圾回收,虚拟机发现没有被引用的对象时,就会对堆中对象进行垃圾回收,以释放内存空间。
方法区:用于存储已被加载的类信息、常量、静态变量、即时编译后的代码等数据的内存区域。每加载一个类,方法区就会分配一定的内存空间,用于存储该类的相关信息,这部分空间随着需要而动态变化。方法区的具体实现形式可以有多种,比如堆、永久代、元空间等。
运行时常量池:是方法区的一部分。用于存储编译阶段生成的信息,主要有字面量和符号引用常量两类。其中符号引用常量包括了类的全限定名称、字段的名称和描述符、方法的名称和描述符。
Java中的对象一定在堆上分配内存吗?
不一定,在HotSpot虚拟机中,存在JIT优化的机制,JIT优化中可能会进行逃逸分析,当经过逃逸分析发现某一个局部对象没有逃逸到线程和方法外的话,那么这个对象就可能不会在堆上分配内存,而是进行栈上分配。
JVM有哪些垃圾回收算法?
标记-清除
标记清除是最简单和干脆的一种垃圾回收算法,他的执行流程是这样子的:当 JVM 识别出内存中的垃圾以后,直接将其清除,但是这样有一个很明显的缺点,就是会导致内存空间的不连续,也就是会产生很多的内存碎片。先画个图来看下
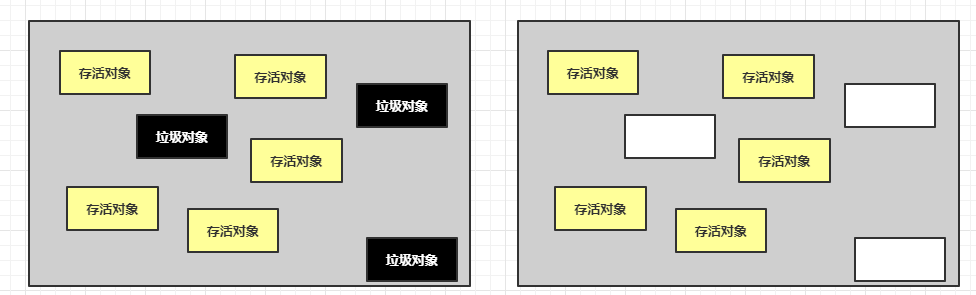
我们使用上图左边的图来表示垃圾回收之前的样子,黑色的区域表示可以被回收的垃圾对象。这些对象在内存空间中不是连续的。右侧这张图表示是垃圾回收过后的内存的样子。可以很明显的看到里面产生了断断续续的 内存碎片。
那说半天垃圾不是已经被回收了吗?内存碎片就内存碎片呗。又能咋地?
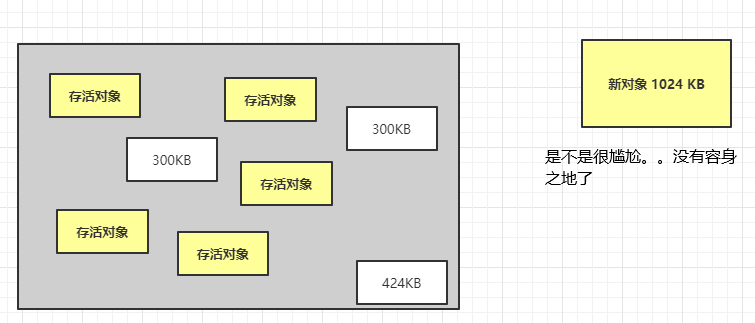
好,我来这么告诉你,现在假设这些内存碎片所占用的空间之和是1 M,现在新创建了一个对象大小就是 1 M,但是很遗憾的是,此时内存空间虽然加起来有 1 M,但是并不是连续的,所以也就无法存放这大对象。也就是说这样势必会造成内存空间的浪费,这就是内存碎片的危害。
比方说其中的1M空间其实依然是可用的,只不过它只能存放<=1M的对象,但是再出现大小完全一模一样的对象是概率很低的事情,即使出现了也并不一定被刚好分配到这段空间上,所以这1M很大概率会被分配给一个<1M的对象,或许只会被利用999K或者1020K或者任意K,剩下的那一点点就很难再被利用了,这才形成了碎片。
这么一说标记-清除就没有优点了吗?优点还是有的:速度快
到此,我们来对标记-清除来做一个简单的优缺点小结:
- 优点
- 速度快,因为不需要移动和复制对象
- 缺点
- 会产生内存碎片,造成内存的浪费
标记-复制
上面的清除算法真的太差劲了。都不管后来人能不能存放的下,就直接啥也不管的去清除对象。所以升级后就来了复制算法。
复制算法的工作原理是这样子的:首先将内存划分成两个区域。新创建的对象都放在其中一块内存上面,当快满的时候,就将标记出来的存活的对象复制到另一块内存区域中(注意:这些对象在在复制的时候其内存空间上是严格排序且连续的),这样就腾出来一那一半就又变成了空闲空间了。依次循环运行。
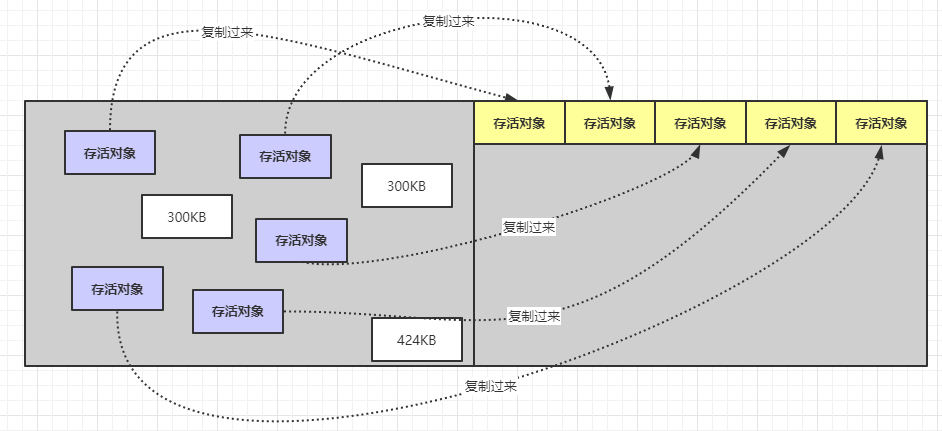
在回收前将存活的对象复制到另一边去。然后再回收垃圾对象,回收完就类似下面的样子:
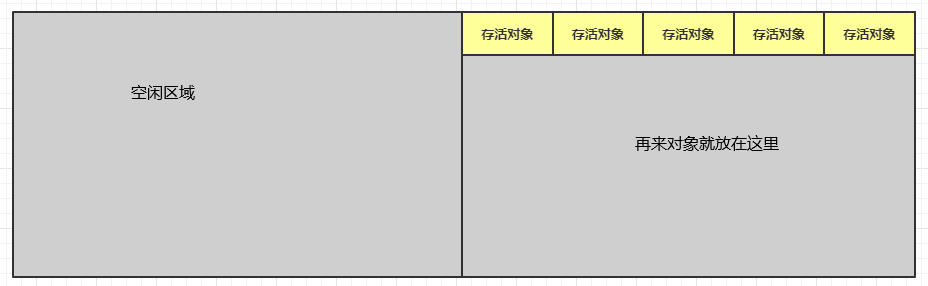
如果再来新对象被创建就会放在右边那块内存中,当内存满了,继续将存活对象复制到左边,然后清除掉垃圾对象。
标记-复制算法的明显的缺点就是:浪费了一半的内存,但是优点是不会产生内存碎片。所以我们再做技术的时候经常会走向一个矛盾点地方,那就是:一个新的技术的引入,必然会带来新的问题。
到这里我们来简单小结下标记-复制算法的优缺点:
- 优点
- 内存空间是连续的,不会产生内存碎片
- 缺点
- 1、浪费了一半的内存空间
- 2、复制对象会造成性能和时间上的消耗
说到底,似乎这两种垃圾回收回收算法都不是很好。而且在解决了原有的问题之后,所带来的新的问题也是无法接受的。所以又有了下面的垃圾回收算法。
标记-整理
标记-整理算法是结合了上面两者的特点进行演化而来的。具体的原理和执行流程是这样子的:我们将其分为2个阶段:
第一阶段为标记;
第二阶段为整理;
标记:它的第一个阶段与标记-清除算法是一模一样的,均是遍历 GC Roots,然后将存活的对象标记。
整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
我们是画图说话,下面这张图是垃圾回收前的样子。
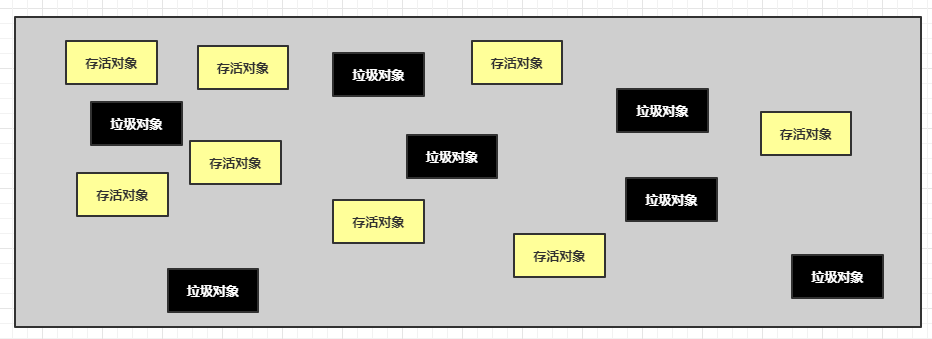
下图图表示的第一阶段:标记出存活对象和垃圾对象
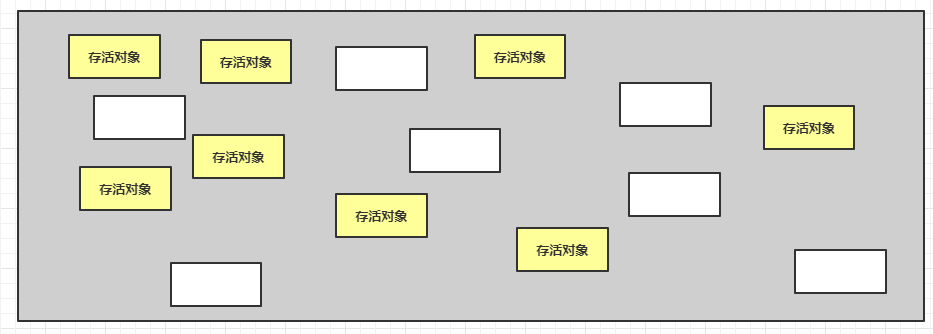
白色空间表示被清理后的垃圾。
下面就开始进行整理:
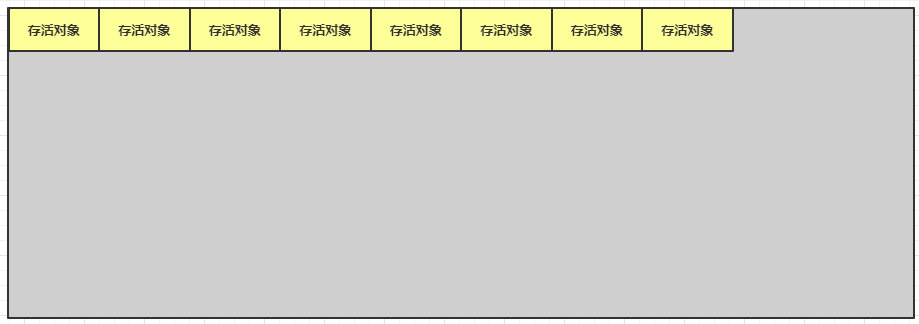
可以看到,现在即没有内存碎片,也没有浪费内存空间。
但是这就完美了吗?他在标记和整理的时候会消耗大量的时间(微观上)。但是在大厂那种高并发的场景下,这似乎有点不尽如人意。
到此,我们将标记-整理的优缺点整理如下:
- 优点
- 1、不会产生内存碎片
- 2、不会浪费内存空间
- 缺点
- 太耗时间(性能低)
到此为止,我们已经了知道了标记-清除、标记-复制、标记-整理三大垃圾回收算法的优缺点。
单纯的从时间长短上面来看:标记-清除 < 标记-复制 < 标记-整理。
单纯从结果来看:标记-整理 > 标记-复制 >= 标记-清除
什么是强引用、软引用、弱引用和虚引用?
在 Java 中,引用类型决定了对象在垃圾回收(GC)中的行为。Java 提供了 四种引用类型,分别适用于不同的场景,它们的特点和使用场景如下:
强引用
特点:
- 最常见的引用类型,只要对象存在强引用,GC 不会回收该对象。
- 即使内存不足,JVM 会抛出
OutOfMemoryError异常,也不会回收强引用对象。
使用场景:
- 日常开发中的普通对象(如
Object obj = new Object())。 - 核心对象(如数据库连接池)需要长期存活。
- 日常开发中的普通对象(如
代码示例:
Object obj = new Object(); // 强引用 obj = null; // 手动断开强引用后,对象可被回收
软引用
特点:
- 内存不足时会被回收(在抛出
OutOfMemoryError前触发)。 - 内存充足时,对象不会被回收,适合实现内存敏感的缓存。
- 内存不足时会被回收(在抛出
使用场景:
- 图片缓存、临时数据存储。
- 避免缓存占用过多内存导致 OOM。
代码示例:
import java.lang.ref.SoftReference; String strongRef = new String("Hello, Soft Reference!"); SoftReference<String> softRef = new SoftReference<>(strongRef); strongRef = null; // 断开强引用 String value = softRef.get(); if (value != null) { System.out.println(value); // 内存充足时输出值 } else { System.out.println("Object has been collected"); // 内存不足时输出 }
弱引用
特点:
- 无论内存是否充足,下一次 GC 时立即回收。
- 适合存储临时性数据,对象生命周期短。
使用场景:
WeakHashMap的键(用于实现缓存,键值对自动清理)。- 避免内存泄漏(如监听器或缓存)。
代码示例:
import java.lang.ref.WeakReference; Object obj = new Object(); WeakReference<Object> weakRef = new WeakReference<>(obj); obj = null; // 断开强引用 System.gc(); // 触发 GC System.out.println(weakRef.get()); // 输出: null(对象已被回收)
虚引用
特点:
- 无法通过
get()获取对象(始终返回null)。 - 对象被回收时,通过
ReferenceQueue收到通知。 - 主要用于跟踪对象被回收的时机。
- 无法通过
使用场景:
- 资源清理(如文件句柄、数据库连接)。
- 实现类似
Cleaner的机制(Java 9+ 已弃用PhantomReference,推荐使用Cleaner)。
代码示例:
import java.lang.ref.PhantomReference; import java.lang.ref.ReferenceQueue; ReferenceQueue<Object> queue = new ReferenceQueue<>(); Object obj = new Object(); PhantomReference<Object> phantomRef = new PhantomReference<>(obj, queue); obj = null; // 断开强引用 System.gc(); // 触发 GC // 检查引用队列 if (queue.poll() != null) { System.out.println("Object has been collected"); // 输出回收通知 }
垃圾回收器
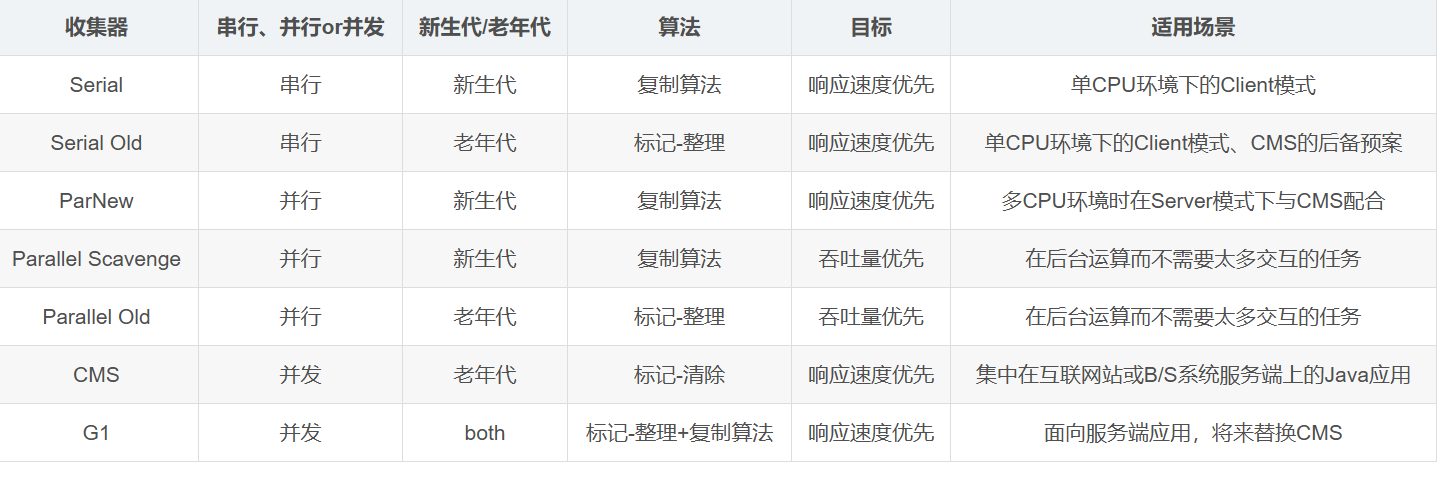
ZGC有什么特点?
arbage Collector)是Java 11中引入的一种新的垃圾回收器,他是一个为了实现低延迟而设计的垃圾收集器,具有以下几个特点:- 低停顿:ZGC的目标是保证暂停时间非常短,ZGC 的目标是保持最大暂停时间在亚毫秒级,且这个暂停时间不会随着堆、live-set 或 root-set 的大小而增加。
- 高吞吐量:ZGC 是一个并发垃圾收集器,意味着大部分垃圾收集工作都是在 Java 线程继续执行的同时完成的。这极大地减少了垃圾收集对应用程序响应时间的影响。
- 兼容性:ZGC与现有的Java应用程序完全兼容,并且无需更改代码即可使用。但是也有一定的限制,仅支持 Linux 64位系统,不支持 32位平台。不支持使用压缩指针,采用内存分区管理。
- 简单性:ZGC设计简单,代码库较小,因此它更容易维护和扩展。
- 支持大堆:ZGC 能处理从 8MB 到 16TB 大小的堆,适用于大规模内存需求的应用程序
- 不分代回收:ZGC在垃圾回收时对全量内存进行标记,但是回收时仅针对分内存回收,优先回收垃圾比较多的页面。
类的生命周期
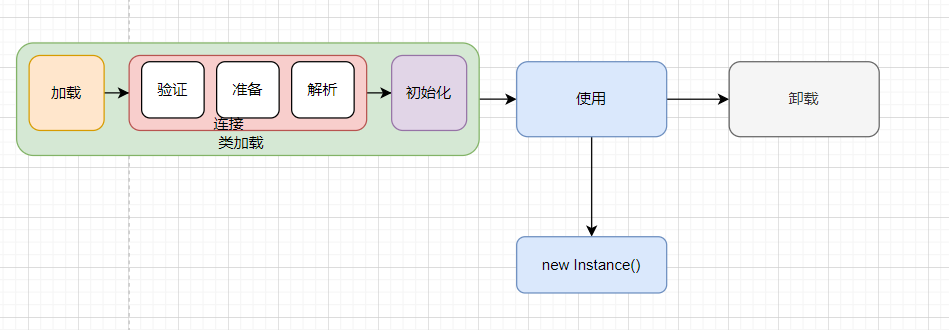
| 阶段 | 目标 | 关键点 |
|---|---|---|
| 加载 | 加载字节码文件 | 生成 Class 对象,触发类加载器工作 |
| 验证 | 检查字节码合法性 | 防止非法代码对 JVM 造成危害 |
| 准备 | 分配静态变量内存并设置默认值 | 静态变量默认值为零值(非代码中定义的值) |
| 解析 | 符号引用转为直接引用 | 方法、字段、类的符号引用转换为内存地址 |
| 初始化 | 执行静态变量赋值和静态代码块 | 按顺序初始化静态变量,执行静态代码块 |
| 使用 | 创建对象、调用方法 | 类被应用程序实际使用 |
| 卸载 | 释放类占用的资源 | 依赖类加载器和实例的回收,卸载概率较低 |
什么是双亲委派?如何破坏?
下图中展示的类加载器之间的这种层次关系,称为类加载器的双亲委派模型(Parents Delegation Model)。
双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。这里类加载器之间的父子关系一般不会以继承(Inheritance)的关系来实现,而是都使用组合(Composition)关系来复用父加载器的代码。
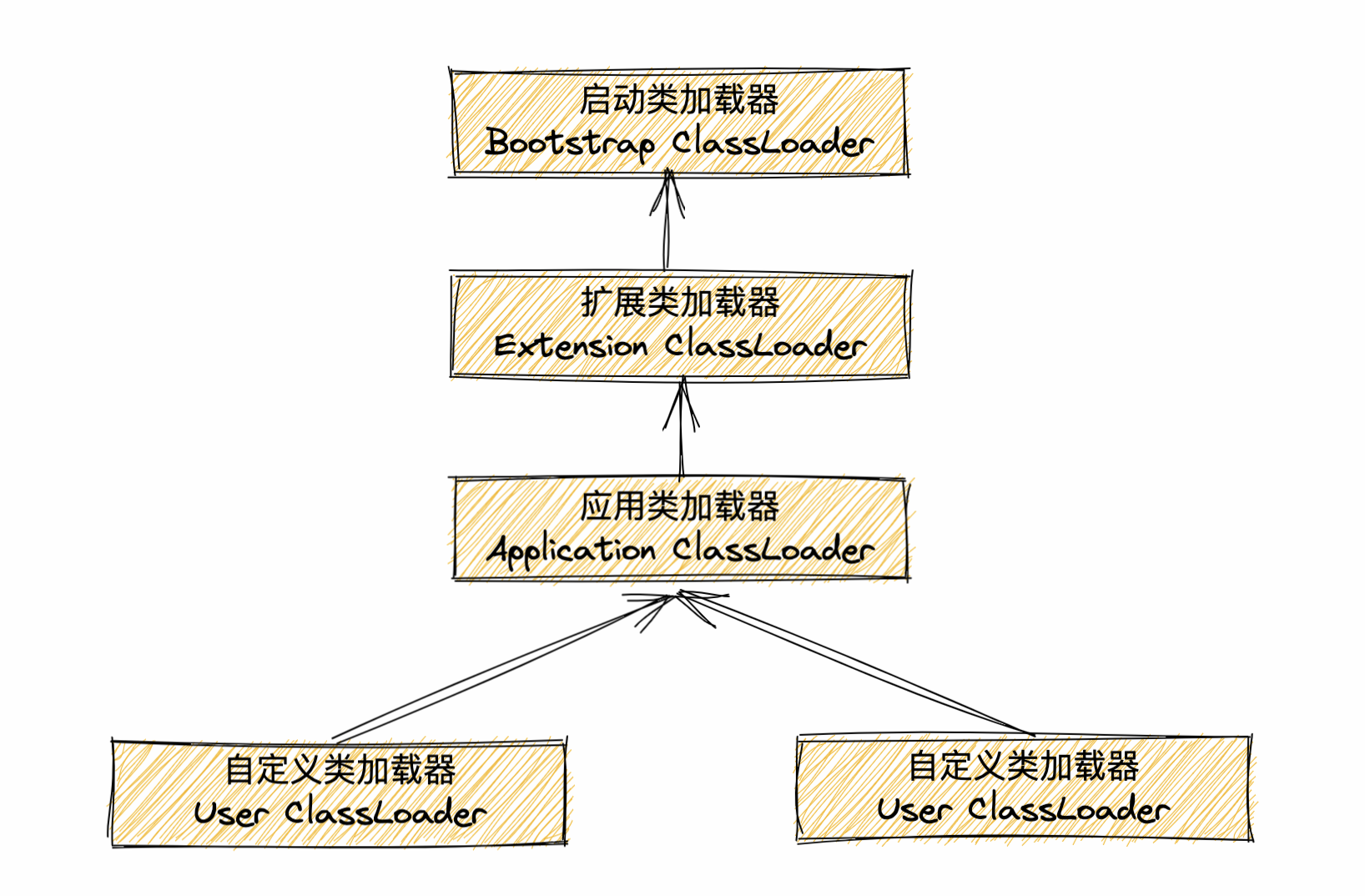
双亲委派模型的工作过程是:
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
双亲委派模型对于保证Java程序的稳定运作很重要,但它的实现却非常简单,实现双亲委派的代码都集中在java.lang.ClassLoader的loadClass()方法之中,代码简单,逻辑清晰易懂:先检查类是否已经被加载过,若没有加载则调用父加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父类加载失败,抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
findClass用于重写类加载逻辑、loadClass方法的逻辑里如果父类加载器加载失败则会调用自己的findClass方法完成加载,保证了双亲委派规则。
1、如果不想打破双亲委派模型,那么只需要重写findClass方法即可
2、如果想打破双亲委派模型,那么就重写整个loadClass方法
虚拟机中的堆一定是线程共享的吗?
为了保证对象的内存分配过程中的线程安全性,HotSpot虚拟机提供了一种叫做TLAB(Thread Local Allocation Buffer)的技术。
在线程初始化时,虚拟机会为每个线程分配一块TLAB空间,只给当前线程使用,当需要分配内存时,就在自己的空间上分配,这样就不存在竞争的情况,可以大大提升分配效率。
所以,“堆是线程共享的内存区域”这句话并不完全正确,因为TLAB是堆内存的一部分,他在读取上确实是线程共享的,但是在内存分分配上,是线程独享的。
TLAB的空间其实并不大,所以大对象还是可能需要在堆内存中直接分配。那么,对象的内存分配步骤就是先尝试TLAB分配,空间不足之后,再判断是否应该直接进入老年代,然后再确定是再eden分配还是在老年代分配。
字符串常量池
在JDK 1.6及之前的版本,字符串常量池通常被实现为方法区的一部分,即永久代(Permanent Generation),用于存储类信息、常量池、静态变量、即时编译器编译后的代码等数据。
从JDK 1.7开始,字符串常量池的实现方式发生了重大改变。字符串常量池不再位于永久代,而是直接存放在堆(Heap)中,与其他对象共享堆内存。
之所以要挪到堆内存中,主要原因是因为永久代的 GC 回收效率太低,只有在FullGC的时候才会被执行回收。但是Java中往往会有很多字符串也是朝生夕死的,将字符串常量池放到堆中,能够更高效及时地回收字符串内存
运行时常量池和字符串常量池
- 运行时常量池是类加载的核心数据结构,存储所有类的符号引用和字面量,是 JVM 动态链接的基石。
- 字符串常量池是运行时常量池中字符串字面量的实际存储区域,通过全局共享机制节省内存。
- JDK 7 的变化将字符串常量池从方法区移至堆内存,解决了永久代的内存瓶颈问题,同时优化了字符串的管理和回收效率。
什么是逃逸分析?
在Java中,不同的逃逸状态影响JIT(即时编译器)的优化策略:
- 全局逃逸(GlobalEscape):由于对象可能被多个线程访问,全局逃逸的对象一般不适合进行栈上分配或其他内存优化。但JIT可能会进行其他类型的优化,如方法内联或循环优化。(方法内联参考:https://www.yuque.com/hollis666/xkm7k3/nkr4ge#ovn99 )
- 参数逃逸(ArgEscape):这种情况下,对象虽然作为参数传递,但不会被方法外部的代码使用。JIT可以对这些对象进行一些优化,例如锁消除
- 无逃逸(NoEscape):这是最适合优化的情况。JIT可以采取多种优化措施,如在栈上分配内存,消除锁,甚至完全消除对象分配(标量替换)。这些优化可以显著提高性能,减少垃圾收集的压力。